Abstracts from the SilverPlatter LISA database were analyzed to determine formulaic phrases used repeatedly over time. About 25 phrases were identified. Few agreements were found with the formulas used in the FABS abstracting formulary. A study of ERIC abstracts showed similar results, though with fewer phrases being identified. Displays of formulaic phrases have been incorporated as a feature in the TEXNET computer-assisted abstracting package.
Suggestions for purely automatic abstracting methods, as surveyed by Paice [1] and Endres-Niggemeyer [2], do not show immediate promise of totally superseding human effort. An appropriate short-term goal would seem to be a hybrid system, in which some tasks are performed by human abstractors and other tasks by software. The model of such hybrid abstracting with which this article is concerned involves providing writers of conventional abstracts with various computerized tools to assist them.
Abstracting-assistance tools can include the sort of computerized tools already commonly provided for writing tasks in general. Examples of computerized writing-assistance tools are word processors, spell-checkers, computerized thesauri, grammar and style checkers, outliners, graphic (hypertext) tools, and rhetorical prompters [3] [4] [5] [6].
Some types of computerized abstracting-assistance tool, however, will need to be specially designed for the abstracting task. An example of such a tool is an automatic extractor: human abstractors may be able to make good use of automatic extracts as starting points for building their own abstracts. This and several other specialized tools have already been incorporated into the experimental TEXNET text abstracting assistance system, described elsewhere [7] [8].
This article is concerned with development of another tool of this latter type: a display of formulaic expressions among which the abstractor may select for inclusion in abstracts. Several topics will be considered: extraction of formulaic phrases from a database of abstracts; measures that might be applied to determine formula density in abstracts; and provisions for display of formulaic phrases in TEXNET.
For an initial study of possible formulas in abstracts, the SilverPlatter version of the LISA database was used. All 908 abstracts for 1991, the last year covered, were analyzed.
Phrase counting was performed entirely in computer memory, using a method similar to that described for INDEX [9]. Although this method makes highly efficient use of memory available, processing time was found to increase precipitously and unacceptably at around the 500-abstract mark. Accordingly, the abstracts from 1991 were divided, by means of a pseudo-random number generator, into two sets of 461 and 447 abstracts respectively.
It was apparent that a number of repeated phrases in each abstract set were time-bound, representing common references to a conference theme, journal issue, or the like. For instance, 15 of the abstracts from the 1991 sets all were found to begin with the words CONTRIBUTION TO AN ISSUE DEVOTED TO INFORMATION SOURCES ON. In the second set alone, there were 17 occurrences of the sequence THE NORTH AMERICAN SERIALS INTEREST GROUP 5TH ANNUAL CONFERENCE 2-5 JUNE 90 ST CATHERINES ONTARIO ON THE FUTURE OF SERIALS.
To filter out the temporary formulas, documents from different times can be employed. The database used in this case provided no simple way of obtaining a random sample or abstracts over a longer period. Thus, it was decided to eliminate temporary formulas by selecting only those phrases that were frequent in two sets of abstracts, each set from a year widely separated from the other.
The two years chosen were 1974, the first year for which a substantial number of abstracts were provided, and 1991. Because of the small number of abstracts provided for 1974, 254 out of 2901 records, all were considered, and the threshold for a frequent phrase was set at 5 instances. For 1991, the sample of 461 abstracts was used with a threshold of 10 instances. The threshold in each case represented approximately 1 occurrence per 45 abstracts. The result was a set of 468 phrases, of which 129 consisted of more than 1 word, with none consisting of more than 5 words.
Phrases selected by this step were compared with phrases included in the FABS abstracting formulary developed by Harris and Harris and Hofmann [10] for documents in linguistics. Only the following 13 agreements were found:
The remaining phrases given in the FABS formulary, about 60, had no exact counterparts in the list derived from the LISA abstracts.
Even among phrases that remain frequent over time in a given field, many are not in fact suited to display in a menu. Two categories became fairly obvious candidates for elimination. The first was single significant words, such as ACTIVITIES or BIBLIOGRAPHIC; the second was short phrases consisting only of obvious stopwords, such as AND A or AT THE. In either case, it would probably be easier for the abstractor to simply type the phrase, which would be short or familiar, than to find it in a menu.
To eliminate such phrases, a further filtering process was defined. All stopwords were assigned one weight, and all non-stopwords were assigned another, higher, weight. Each phrase received a score equal to the sum of the weights of its constituent words. For the phrase to be accepted, its score was required to be equal to or greater than a threshold.
This filter was applied to the sample set with a stoplist of about 140 words, a stopword weight of 1, a non-stopword weight of 10, and a threshold of 12. As a result, the number of phrases was reduced to 25, with some overlap. This included a few phrases like AB DESCRIBES THE, in which AB is a pseudo-word marking the beginning of the abstract; these were considered worth retaining on the grounds that abstractors might be especially interested in being presented with formulas for this position (an idea noted, albeit humorously, by Jeroski and Dartnell [11], for example). One phrase, NUMBERS -, was the result of failing to include the hyphen on the stoplist.
A validity check was performed on the two-year methodology: a proximity search on the entire database was carried out for the phrase PAPER PRESENTED, and the publication-year distribution of the resulting set was determined. The longer phrase PAPER PRESENTED AT THE could not readily be sought because the last two words are stopwords for the retrieval system.
It was originally intended to determine the publication-year distribution by means of the set conjunction operator AND available in the retrieval system. This was found, however, to produce erratic and often absurd results. For example, in four attempts, the count for 1986 was returned twice as 0, once as 205, and only once correctly, as 219. Accordingly, the distribution was in fact determined by writing a special program to analyze a download of the original set limited to the publication-year field. The erratic results with AND were later surmised to have resulted from accessing the CD-ROM via a network.
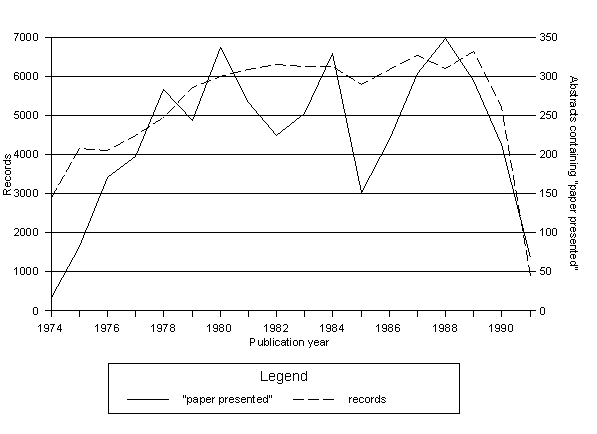
Figure 1: Formulaic Phrase by Publication Year - LISA
Figure 1 shows the resulting distribution, superimposed on the corresponding distribution of all records. It is only in the first two years that the abstracts containing the phrase fall below 2% of all records. Regardless of which of the other years might be chosen in the two-year method, the phrase would still be selected.
The apparent shortfall for the phrase in the first two years is in fact a result of the small proportion of records with abstracts for those years. This observation led to the question whether the same factor might account for some of the fluctuation in the remainder of the distribution. A random sample of 50 records was therefore examined from 1985, the year in which the phrase occurrences dropped most radically relative to total records. No records in the sample, however, proved to have empty abstract fields.
Since the use of author abstracts by abstracting services appears to be becoming more frequent generally, one might hypothesize that the abstracts would be becoming less formulaic. To obtain a preliminary indication of whether such a hypothesis might be worth pursuing, certain statistical measures were applied to the sample abstract files.
The first measure was l, an inverse measure of diversity due to Simpson [12]. This equals the probability that any two different word occurrences chosen at random from the text are of the same word. As well as being relatively easy to calculate and interpret, this measure has the advantage of being unbiased by sample size.
For the two samples of abstracts from 1991, the values of l were identical to 3 significant digits, at 0.00104 and 0.00104; for the abstracts from 1974, l was slightly higher at 0.00164. Restricting allowed characters in words to letters of the alphabet, excluding numerals, produced little change: 0.00103 for both samples in 1991 and 0.00167 for 1974. Although no significance test was performed, these results do indicate that the vocabulary was more diverse in the later abstracts.
Measurement of diversity of longer phrases was also undertaken. Likely the easiest to understand of the additional measures used is the probability that two randomly chosen two-word phrases are identical. This was found to be 0.000295 and 0.000214 for the 1991 samples and 0.000416 for 1974; restricting to letters of the alphabet produced values of 0.000266 and 0.000193 for 1991 and 0.000542 for 1974. Again, diversity is higher for the later abstracts. The difference between the values for the two 1991 sets and the smaller number of identical pairs on which the measure is based suggest that any statistical significance would be lower.
The diversity of phrases depends of course at least partly on the diversity of words. This factor can be eliminated by dividing by the squares of the respective l values. The results of this procedure are 274 and 196 for 1991 and 196 for 1974, or, restricting to letters, 251 and 181 for 1991 and 194 for 1974. Here, no clear trend emerges.
Following the study of LISA abstracts, a similar study was carried out on samples of ERIC abstracts. Three sets of abstracts were examined: one of 469 abstracts in 470 records from 1995 (EJ493700-EJ494169); one of 497 abstracts in 497 records from around 1980 (EJ250664-EJ251160); and one of 407 abstracts in 470 records from 1974 (EJ100000-EJ100469). Although the ERIC database goes back to 1966, it was evident, as in the case of LISA, that the earliest records often lacked abstracts.
Time-bound repeated phrases were not evident in examining the 1995 ERIC sample. Nevertheless, the first filtering process previously described for LISA was applied again here for consistency.
Matching of phrases thus selected against the FABS formulary yielded almost the same agreements as in the case of LISA; the exceptions were that ANALYSES (ANALYZES) was omitted and that BASED ON was selected only when the 1995 sample was filtered against the 1980 sample.
Application of the second filtering process, involving weighting, yielded a considerably smaller set of phrases (7 to 9) than with LISA.
The values of l for the 1974, 1980, and 1995 samples were 0.00246, 0.00144, and 0.00119 respectively, showing again an increase in vocabulary diversity over time. The probabilities of two random two-word phrases being identical were 0.000469, 0.000321, and 0.000222. Dividing these values by the squares of the respective l values yielded results of 77.4, 154, and 158; thus, in the earliest sample, that from 1974, the component of phrase diversity that did not depend on word diversity was about twice what it was in the other two samples.
Among other types of extract, the TEXNET user may call up a compact display of common phrases from the full-text being abstracted. The automatic phrase extraction procedure is described more full elsewhere [13]. Some general tendencies may be noted here. First, all "frequent", and no "infrequent", non-stopwords are selected as one-word phrases. Second, no selected phrase consists only of stopwords. Third, a selected phrase may contain stopwords, including at its beginning or end: it must simply score sufficiently highly on density of frequent non-stopwords.
Compactness of display is achieved by not displaying separately any phrase that is a subphrase of another extracted phrase. It is still desirable that the user should find it easy to select any of the phrases, long or short, for inclusion in the abstract. To this end, the user is permitted to move from word to word, or to select a word and move on to the next, with a single keystroke.
The TEXNET software was modified to allow loading of a list of formulaic phrases and their display in the same compact form as used for phrases common within a document. Figure 2 shows the compact display produced from the reduced list for the LISA sample data.
Figure 2 
Several methods of phrase extraction for purposes of indexing and information retrieval have been described [14] [15]. The task undertaken in this exploration, however, is in some ways diametrically opposed in its aims. Formulaic phrases such as "paper presented at the" are generally of little use in indexing or information retrieval. At the same time, certain general techniques, such as counting of frequency and penalization of stopwords are applicable to both kinds of extraction.
A previous study [16], based on a small number of abstracts on computer software, suggested little use of frequent formulaic words. Thus, it was not surprising that few formulas emerged in the present study.
The relatively short final list of formulas derived suggests the possibility of different treatments. A professional abstractor might be expected to memorize the list quite quickly. Such a user might find it efficient to be able to refer to formulaic phrases by code or abbreviation without even viewing the display. The graphic display, however, might remain as an option for infrequent abstractors or for fields in which more formulas were found.
In extracting phrases from individual full texts, a maximum length of seven words was found to be not always sufficient. Longer significant repeated sequences were in fact observed in sample documents. This does not, however, appear to hold true within collections of abstracts over a longer period of time: durable formulaic phrases, if any, tend to be rather short.
In general, basing the selection on two years' abstracts only does hold some measure of risk. For example, the two years might just happen to coincide with the publication of voluminous proceedings from two occasional conferences in a series. Random sampling is therefore to be preferred where feasible. If the two-year method is adopted, proximity searching on extracted phrases followed by determination of publication-year distributions of the resulting sets may be used as a check.
A possible shortcoming of the LISA data used lies in the sparse nature of the abstracting for 1974. As already noted, only a relatively small proportion of the items indexed for that year in fact had abstracts. A bias may exist in which items these were. The subsequent use of ERIC data, in which early, sparsely abstracted years were deliberately avoided, largely overcomes this difficulty.
Radziewskaya [17] has pointed to the association of certain words or stems with particular content types within abstracts, and this is borne out by the work of Liddy [18]. Some cue words of this type were observed in the data from both the LISA and the ERIC abstracts; for example, ANALYSES in LISA and EXAMINES, RESULTS, SUGGESTS in both. The short list of multi-word phrases from LISA also includes a number of content-indicative elements. The work of Tibbo [19] indicates considerable variation in abstract content types between disciplines; thus, such a set of phrases should probably vary with the field.
The formulaic was sought in this study on a very superficial level. Use was not even made of stemming, which might have revealed some frequent patterns differing only between singular and plural. It had also been observed that Paice [20], in his work on automatic abstracting, had made some use of intervening variable elements within cue phrases. One conceivable approach would be clustering of phrases using a similarity measure such as that described by Sheridan & Smeaton [21]. Nevertheless, it was decided not to pursue this possibility further at this time, since it seemed unlikely to yield many significant results.
Formulas at deeper levels might be detected by use of a thesaurus. It is recognized that abstractors, like other writers, often engage in aesthetic variation of expression. Many computer text generation systems simulate such variation; Paice and Jones [22] in fact suggest it for the production of automatic abstracts. A thesaurus might allow detection of conceptual formulas. One possible use of the results might be to provide the abstractor with a menu of codes for conceptual formulas, with the computer automatically inserting an aesthetic variant phrase. The thesaurus used might be one conventionally generated by human analysis or one produced automatically on the basis of cooccurrences, as in the TINA project [23].
The LISA abstracts are almost entirely in natural language, with few codes, abbreviations, formulas, or symbols. This is not true of abstracts from all other services, however. Menus of special codes and abbreviations to be used in abstracts, like those proposed by Trawinski [24], might be added where appropriate.
Another kind of menu would relate more specifically to ensuring appropriate abstract content. Abstracts in the field of medicine, for example, have been found often to be missing major content elements [25]. In response, several medical journals have adopted common guidelines for abstracts divided into sections, each preceded by a standard heading [26]. Where appropriate, such a set of headings could be provided automatically as a template for abstract writers.
Finally, changes in vocabulary and phrase diversity, examined in a very tentative manner in this study, might in the future form the subject of a much more extensive research undertaking.
Research reported in this article was supported in part by individual operating grant A9228 of the Natural Sciences and Engineering Research Council of Canada.
The TEXNET software described in this article is written as a MicroSoft Windows application in Borland Pascal with Objects 7.0. Either source or executable code is available by sending a 5 1/4" or a 3 1/2" dual-density diskette to the author: both may be obtained if two dual-density or one high-density diskette is sent.
[1] C. Paice, Constructing literature abstracts by computer: techniques and prospects, Information processing and management, 26 (1) (1990) 171-186.
[2] B. Endres-Niggemeyer, Summarizing text for intelligent communication: results of the Dagstuhl Seminar, Knowledge organization, 21 (4) (1994) 213-223.
[3] R.B. Kozma, The impact of computer-based tools and embedded prompts on writing processes and products of novice and advanced college writers, Cognition and instruction, 8 (1) (1991) 1-27.
[3] C. Neuwirth, and D. Kaufer, The role of external representations in the writing process: implications for the design of hypertext-based writing tools, Hypertext '89 proceedings (ACM, Baltimore, Maryland, 1989) 319-341.
[5] J. Payette, and G. Hirst, An intelligent computer-assistant for stylistic instruction, Computers and the humanities, 26 (2) (1992) 87-102.
[6] R Rada, and G-N You, Balanced outlines and hypertext, Journal of documentation, 48 (1) (1992) 20-44.
[7] T.C. Craven, A computer-aided abstracting tool kit, Canadian journal of information science, 18 (2) (1993) 19-31.
[8] T.C. Craven, A thesaurus as part of a computer-aided abstracting tool kit. In: S. Bonzi, J. Katzer, and B.H. Kwasnik (eds), ASIS '93: proceedings of the 56th ASIS Annual Meeting (1993, volume 30), Columbus, Ohio, October 22-28, 1993 (Learned Information, Medford, New Jersey, 1993) 178-184.
[9] L.P. Jones, E.W. Gassie, and S. Radhakrishnan, INDEX: the statistical basis for an automatic conceptual phrase-indexing system, Journal of the American Society for Information Science, 41 (2) (1990) 87-97.
[10] B. Harris, and T.R. Hofmann, FABS (formulated abstracting): an experiment in regularized content description, Open Conference on Information Science in Canada proceedings, 1 (1973) 17-27.
[11] S. Jeroski, and D. Dartnell, The anti-verb list, Journal of the American Society for Information Science, 29 (3) (1978) 158.
[12] E.H. Simpson, Measurement of diversity, Nature, 163 (1949) 688.
[13] T.C. Craven, Presentation of repeated phrases in a computer-assisted abstracting tool kit, Information processing and management (Accepted for publication).
[14] R. Burgin, and M. Dillon, Improving disambiguation in FASIT, Journal of the American Society for Information Science, 43 (2) (1992) 101-114.
[15] J.L. Fagan, The effectiveness of a nonsyntactic approach to automatic phrase indexing for document retrieval, Journal of the American Society for Information Science, 40 (2) (1989) 115-132.
[16] T.C. Craven, Use of words and phrases from full text in abstracts, Journal of information science, 16 (1991) 351-358.
[17] T.V. Radziewskaya, Texts of abstracts considered in a linguopragmatic aspect, Automatic documentation and mathematical linguistics, 20 (4) (1986) 55-63.
[18] E.D. Liddy, The discourse-level structure of empirical abstracts: an exploratory study, Information processing and management, 27 (1) (1991) 55-81.
[19] H.R. Tibbo, Abstracting across the disciplines: a content analysis of abstracts from the natural sciences, the social sciences, and the humanities with implications for abstracting standards and online information retrieval, Library and information science research, 14 (1) (1992) 31-56.
[20] C.D. Paice, The automatic generation of literature abstracts: an approach based on the identification of self-indicating phrases. In: Oddy RN, and others (eds), Information retrieval research (Butterworths, 1981) 172-191.
[21] P. Sheridan, and A.F. Smeaton, The application of morpho-syntactic language processing to effective phrase matching, Information processing and management, 28 (3) (1992) 349-369.
[22] C.D. Paice, and P.A. Jones, The identification of important concepts in highly structured technical papers. In: R. Korfhage, E. Rasmussen, and P. Willett (eds), SIGIR '93: proceedings of the Sixteenth Annual International ACM SIGIR Conference on Research and Development in Information Retrieval (ACM Press, Baltimore, MD, 1993) 69-78.
[23] G. Ruge, A spreading activation network for automatic generation of thesaurus relationships, Library science with a slant to documentation, 28 (4) (1991) 125-130.
[24] B. Trawinski, A methodology for writing problem structured abstracts, Information processing and management, 25 (6) (1989) 693-702.
[25] F. Salager-Meyer, Discoursal flaws in medical English abstracts: a genre analysis per research- and text-type, Text, 10 (4) (1990) 365-384.
[26] B.B. Haynes, C.D. Mulrow, E.J. Huth, D.G. Altman, and M.J. Gardner, More informative abstracts revisited, Annals of internal medicine, 113 (1) (1990) 69-76.
| Notes, 2002 |
|---|
| The compact listing of formulaic phrases was an option in TexNetF, the
16-bit version of TexNet, which is still available for download from http://publish.uwo.ca/~craven/freeware.htm#texnetf.
It has not been implemented in TexNet32.
The following is an example of a short formula input file THE 2197 .DEVELOPMENT 26 ..OF 22 .ROLE 24 ..OF 22Such a file could be produced using the ExtPhrW phrase extraction package. |
 Home
Home